自作言語 Momonga のインタプリタをRust + WebAssembly で実装した話
言語処理系や Rust の学習のために、Momonga (モモンガ) という自作言語を 実装していたのですが、この度、Playground として動かせるようになりました。
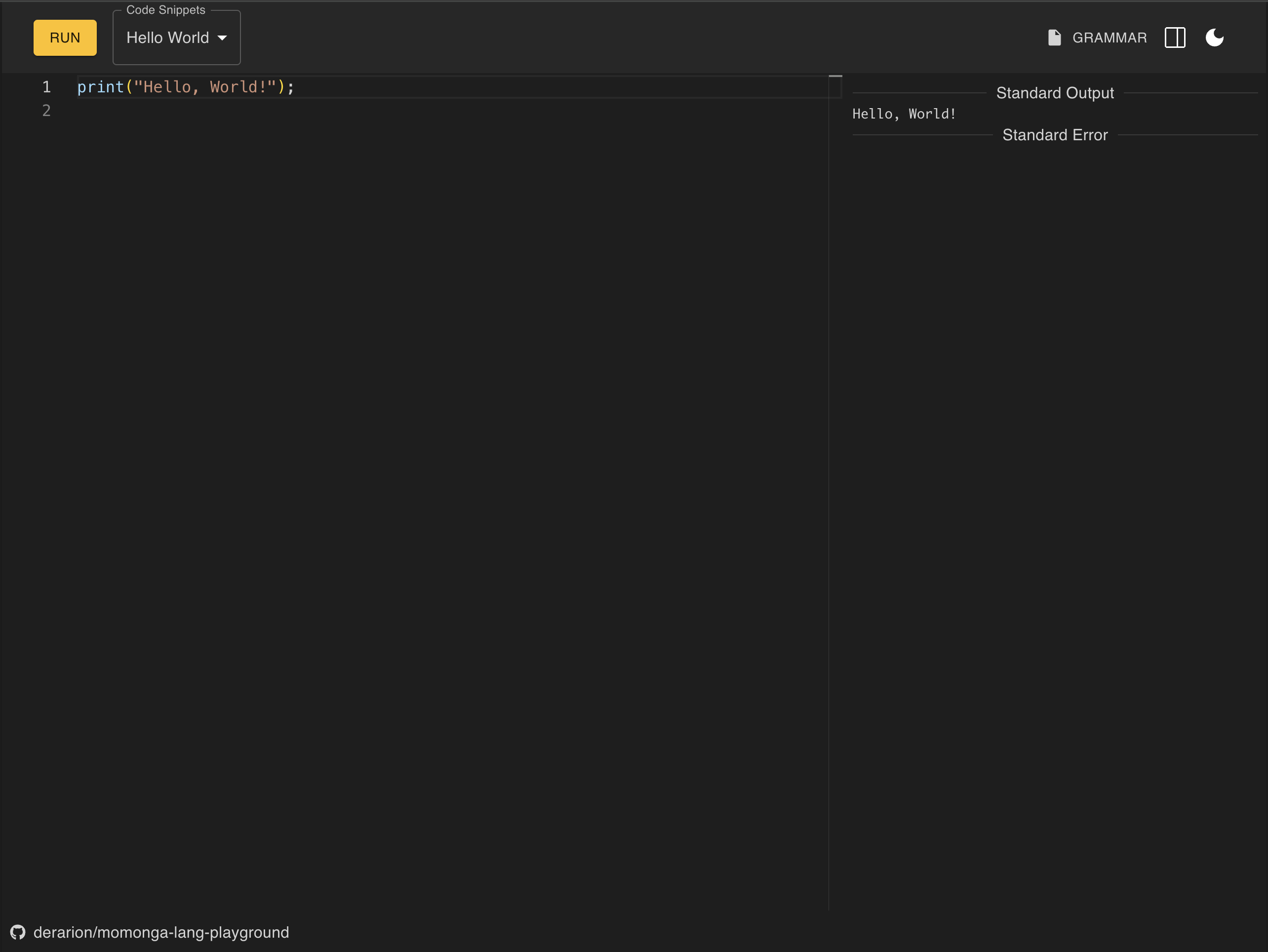
ぜひ遊んでみてください!
もともとあった Rust 製 Momonga を WebAssembly にコンパイルして、ブラウザで実行可能にしました。フロントエンドは React で簡単に作っています。
Momonga は、私が考える初学者フレンドリーなプログラミング言語で、そのコンセプトや言語仕様に関しては以前の記事でご紹介しているので、今回は実装面を主に書きたいと思います。
自作言語ネタは多いので、オリジナリティのありそうなところに焦点をあててみたいと思います。
Rust と WebAssembly を選んだ理由
下記、Momonga の3大コンセプトです。
- 基本的で一般的な構文のみをもつ
- 必要最低限の概念のみをもつ
- 環境構築不要で、オンライン実行環境がある
初学者は実行環境構築で挫折することが多いので、最も普及した実行環境である Web ブラウザ上ですぐに実行できるのが理想でした。
(JavaScript で eval() とかはしないので)必然的に何らかの言語を WebAssembly にコンパイルして実現する考えに至ります。
なお、プログラムソースをバックエンドに渡して実行結果のみ返すタイプのプログラミング学習環境(例えば、paiza.io)もありますが、無料で運用できず、遅延等も起きそうなので却下となりました。以前は、オンラインでブラウザ上にプログラミング環境を作るとなると、この方法くらいしかなかったと思いますが、WebAssebly はこういう面でも夢を広げてくれますね。
WebAssembly はそのサンドボックス環境により、任意コードをブラウザで実行する際のセキュリティリスクを軽減できる点も都合が良かったです。
Wasm コンパイル 可能なものから選ぶことになりますが、メモリ安全やパフォーマンスを考えると、Rust を選ぶことになりました。
実装開始時点でこれらの技術の経験はありませんでしたが、以前、低級言語の学習として有名な『低レイヤを知りたい人のための C コンパイラ作成入門』をやっていて、C 言語 の仕様レベルでのセキュリティリスクを Rust がどのように払拭するのか(後述)も大変興味がありました。WebAssembly も JavaScript の牙城を崩す可能性のある技術として気になっていました。
結果、これらの技術を選んだことは仕様的に正解だったと思いますし、学びも大変多いものでした。Rust の Borrow Checker や Lifetime とはまだお友達になりきれていないですが、Rust コンパイラが本当に親切で賢く、やっていれば段々わかってきました。パターンマッチの気持ちよさ、安心感も格別でした。
各モジュールでの実装内容
パーサー
Rust 製汎用パーサー Pest の導入
tokenizer や parser は自作せず パーサジェネレーター Pest を使いました。(ペスト菌?のようなキャラがかわいいですね!?)。BNF の解析順序に関する曖昧さを取り除いたPEG を記述すれば、Pest では パーサーを自動生成してくれます。
もちろん Momonga 実装の主目的は個人的学習ですが、以前、四則演算器のパーサーを再帰下降構文解析で実装したときに最低限の概念はわかりましたし、今回は Pest に頼りました。
というのも、単なる四則演算と違い BNF が複雑になることが予想され、また、実装開始段階で言語仕様が確定していなかったため、下記のように PEG ファイルでパーサーを生成できる Pest が都合がよかったです。(Rust 製パーサコンビネータとしては他に nom や combine というのも試しました。)
PEG オンラインエディタがめちゃ便利で、実際の Momonga の PEG を記述したうえで、ソースを入力するとパースしてくれます。
下記のように、エディタの Input に構文規則に合致する文字列を 入力すると Parse されます。
var x = 42;
パース結果はこのようになります。
- program
- stmt > var_stmt
- IDENT: "x"
- expr > literal > INT_LITERAL: "42"
- EOI: ""
このツールのおかげで、PEG に対しパース結果をフィードバックしながら、PEG を精錬できたと思います。
なお、演算子の優先順位は、PEG で表現することができます。例えば、この BNF は乗除算が加減算に優先することを表現しています。
factor : NUMBER | "(" expression ")"
term : factor { ("*" | "/") factor }
expression: term { ("+" | "-") term }
しかし、汎用プログラミング言語のように、演算子に前置・中置・後置のバリエーションがあったり、演算子の種類そのものが増えてくると、PEG がカオスになることが予想されました。
そこで、Pest では演算子の優先順位処理に PrattParser を用いました。Pratt 構文解析は再帰下降構文解析における演算子処理の手法であり、アルゴリズムについては、こちらがわかりやすかったです。
上述した演算子の優先順位を文法に静的に表現するに比べて、こちらは構文解析中に動的に演算子の優先順位を管理する手法と言えます。
lazy_static::lazy_static! {
static ref PRATT_PARSER: PrattParser<Rule> = {
use pest::pratt_parser::{Assoc::*, Op};
use Rule::*;
// Precedence is defined lowest to highest
PrattParser::new()
.op(Op::infix(ASSIGN, Right))
.op(Op::infix(OR, Left))
.op(Op::infix(AND, Left))
.op(Op::infix(EQ, Left) | Op::infix(NOT_EQ, Left) | Op::infix(GT, Left) | Op::infix(GE, Left) | Op::infix(LT, Left) | Op::infix(LE, Left))
.op(Op::infix(ADD, Left) | Op::infix(SUBTRACT, Left))
.op(Op::infix(MULTIPLY, Left) | Op::infix(DIVIDE, Left) | Op::infix(MODULO, Left))
.op(Op::prefix(POS) | Op::prefix(NEG) | Op::prefix(NOT))
.op(Op::postfix(INDEX) | Op::postfix(CALL) )
};
}
Momonga の PEG では演算子を並列に扱っていますが、上記のように precedence を指定することでよしなにやってくれました。これにより PEG が簡潔になります。
AST 構築
Pest が生成したパースツリーPairs<'i, Rule>を再帰的に走査して独自に定義した AST を構築して行きます。
#[derive(Parser)]
#[grammar = "momonga.pest"]
pub struct PestMomongaParser;
pub fn parse(source: &str) -> Result<Program, ParseError> {
match PestMomongaParser::parse(Rule::program, source) {
Ok(mut pairs) => {
let program_pair = pairs.next().unwrap();
let mut ast_builder = AstBuilder::new();
Ok(ast_builder.program(program_pair)?)
}
Err(_e) => Err(ParseError::PestParser),
}
}
AST 構築時の制御フローの管理
これは工夫の一つというか、もっといいやり方があったような気がしますが、AST を構築していると、break / continue /return 文のような、AST の処理順を変えるタイプの Statement があることに気づきました。
それらは parser の内部で
enum AstBuildFlow {
Value, // 通常の式文
Break, // break文
Continue, // contiue文
Return, // return文
}
struct AstBuilder {
flow: AstBuildFlow, // 現在の処理方向
}
のように定義し、AST の処理順を制御しました。
例えば、プログラムのトップレベルで、
break;
をすると、実行(評価)前に検出できます。
なお、例えば javascript でも
❌️ Uncaught SyntaxError: Illegal break statement
となりますが、これもプログラムの評価前に出されるエラーと思われます。
AST(抽象構文木)
文 (Statement) と 式 (expression) を enum で表現する
enumで表現することで、評価器でパターンマッチングが効き、 AST 走査で処理漏れがないことがコンパイル時に保証されます。
文 (Statement)
#[derive(Debug, PartialEq, Clone)]
pub enum Stmt {
#[allow(clippy::enum_variant_names)]
BlockStmt(BlockStmt), // ブロック文
FuncDecl(FuncDecl), // 関数定義文
#[allow(clippy::enum_variant_names)]
IfStmt(IfStmt), // If文
#[allow(clippy::enum_variant_names)]
ForStmt(ForStmt), // For文
// ...
}
式 (expression)
#[derive(Debug, PartialEq, Clone)]
pub enum Expr {
Literal(Literal), // リテラル
Ident(Ident), // 識別子
// ...
// 中置演算子
InfixOp {
kind: InfixOpKind,
lhs: Box<Expr>,
rhs: Box<Expr>,
},
// ...
}
スマートポインタBox<T>で再帰的構造を表現する
AST は再帰的な構造をしているためコンパイル時にサイズを決定できず、ポインタを使う必要があります。上記、Expression の定義で使われている Box<T>は単一の値をヒープに割り当てるポインタです。が、ただのポインタではなく、スマートなポインタ、その名もスマートポインタです。
C 言語の場合を考えると、
typedef struct Expr {
struct Expr* lhs;
struct Expr* rhs;
} Expr;
と同様の構造を定めた場合、利用側では free のし忘れによるメモリリークやダングリングポインタ、2重開放の問題がありました。
Expr* expr = malloc(sizeof(Expr));
free(expr);
printf("%d", expr->lhs->value); // ❌ 実行時にエラー
Rust のスマートポインタは所有権システムと結びついているので、これらの問題をコンパイル時に検出できます。
{
let complex_expr = Box::new(Expr::InfixOp {
kind: InfixOpKind::Multiply,
lhs: Box::new(Expr::InfixOp {
kind: InfixOpKind::Add,
lhs: Box::new(Expr::Literal(Literal::Int(1))),
rhs: Box::new(Expr::Literal(Literal::Int(2))),
}),
rhs: Box::new(Expr::Literal(Literal::Int(3))),
});
// ...
} // ← スコープを抜ける際に、全ての Box が自動的に解放される
Option<T>で「有無」を安全に扱う
Rust には (基本的に)null 参照 はありません。Option<T>は 標準ライブラリで定義された enum であり、下記のように「有無」を表します。
pub enum Option<T> {
None,
Some(T),
}
このように値が存在するかしないかが型システムと結びついているため、所謂ヌルポをコンパイル時に排除することができます。
例えば、if 文の else 句なら、
#[derive(Debug, PartialEq, Clone)]
pub struct IfStmt {
pub condition: Expr,
pub block: BlockStmt,
pub else_clause: Option<IfStmtElseClause>,
}
と表現し、下記のように安全に取り出せます。
// パターンマッチによる安全な処理
match if_stmt.else_clause {
Some(else_clause) => {
// else 句が有る場合の処理
},
None => {
// else 句が無い場合の処理
}
}
評価器と実行環境オブジェクト
評価器 evalは AST を再帰的に走査し、式(expression)の評価、及び、文(statement)の実行を行っていきます。
再帰的 AST 走査とパターンマッチングの活用
プログラムは statement の集合体です。
pub type Program = Vec<Stmt>;
したがって、evalはブロック文の実行から始まります。
pub fn eval<'a>(
program: &'a Program,
env: Rc<RefCell<Env<'a>>>,
) -> Result<Option<Rc<RefCell<Value<'a>>>>, EvalError> {
match eval_block_stmt(program, env) {
Ok(val) => Ok(val),
Err(JumpStmt::Error(eval_error)) => Err(eval_error),
_ => unreachable!(),
}
}
eval_block_stmtは ast.rs に定めた Stmtをパターンマッチングで処理しています。
基本的にはこのように AST ノードの種類に応じて、処理をつないでいく形になります。
fn eval_block_stmt<'a>(block_stmt: &'a BlockStmt, env: Rc<RefCell<Env<'a>>>) -> EvalStmtResult<'a> {
let mut result = Ok(None);
for stmt in block_stmt {
result = match stmt {
Stmt::BlockStmt(block_stmt) => {
let env_block = Rc::new(RefCell::new(Env::new(Some(Rc::clone(&env)))));
eval_block_stmt(block_stmt, Rc::clone(&env_block))
},
Stmt::FuncDecl(func_decl) => eval_func_decl(func_decl, Rc::clone(&env)),
Stmt::IfStmt(if_stmt) => eval_if_stmt(if_stmt, Rc::clone(&env)),
Stmt::ForStmt(for_stmt) => eval_for_stmt(for_stmt, Rc::clone(&env)),
// ...
};
// ...
}
result
}
のようになります。
Env の構造とスコープチェーン
文の実行は eval 関数内だけで完結しません。
例えば、変数宣言文は、評価器が保持する環境 Env に新しい変数を追加するという状態変化、いわゆる副作用を引き起こします。もっと言えば、(命令型の)プログラムの計算とは、このようなプログラム実行環境に対する副作用を通じて目的の結果を得ることだとも言えると思います。
Env はこのように表現しています。
pub type Store<'a> = HashMap<&'a str, Rc<RefCell<Value<'a>>>>;
#[derive(Debug)]
pub struct Env<'a> {
store: Store<'a>,
outer: Option<Rc<RefCell<Env<'a>>>>,
}
Momonga にはブロックスコープがあります。store は現在のスコープの変数を保持する HashMap です。outer は親スコープへの参照で、変数解決時にスコープチェーンを辿るために使います。いわゆるスコープチェーンのイメージを持っていれば、上記のような構造を思いつくのではないでしょうか?
ブロックスコープの形成は、ブロック文の評価時に新しい Env をnewし注入することで実現できました。
fn eval_block_stmt<'a>(block_stmt: &'a BlockStmt, env: Rc<RefCell<Env<'a>>>) -> EvalStmtResult<'a> {
let mut result = Ok(None);
for stmt in block_stmt {
result = match stmt {
Stmt::BlockStmt(block_stmt) => {
let env_block = Rc::new(RefCell::new(Env::new(Some(Rc::clone(&env)))));
eval_block_stmt(block_stmt, Rc::clone(&env_block))
},
// ...
};
// ...
}
result
}
AST の種類に応じた eval 系の関数は Envインスタンスを複数箇所から参照しつつ、変数の値を更新する必要があるため、Rc<T> とRefCell<T>のハイブリッドであるRc<RefCell<T>> を使っています。
なお、スコープチェーンにおける変数の解決は下記のようになります。
pub fn get(&self, name: &str) -> Result<Rc<RefCell<Value<'a>>>, EvalError> {
match self.store.get(name) {
Some(val) => Ok(Rc::clone(val)),
None => match &self.outer {
Some(env) => env.borrow().get(name),
None => Err(EvalError::Name),
},
}
}
この実装をしていたときに感じたのは、スコープチェーンやクロージャが、そういう仕様が存在したから実装したというより、そう実装するのが自然だったからそういう仕様になったのでは?ということでした。
特にクロージャは最初に知った時には少し技巧的(直感的じゃない)と感じていたので、勝手に妙に納得しました。どんな言語やフレームワークも、ソースこそが仕様であると感じますね。
なので、Momonga は初学者用の言語でクロージャの理解は不要かなと思いますが、それでもクロージャは自然と利用可能になりました。
MDN のクロージャの例にならうと、
func init() {
var name = "Momonga"; // `name` is a local variable of init()
func printName() {
print(name); // Use variable declared in the parent function
}
printName();
}
init(); // Momonga
となります。
暗黙の型変換をしない
Momonga の特徴として、暗黙の型変換を行わないことにあります。型の不一致はエラーとして処理し、初学者にデータ型の意識を根付かせるためです。
例えば等価演算なら、異なる型同士(例: 1 == "1" や true + 1)は Type error になります。
//...
}
InfixOpKind::Eq => {
match (
&*eval_expr(lhs, Rc::clone(&env))?.borrow(),
&*eval_expr(rhs, Rc::clone(&env))?.borrow(),
) {
(Value::Bool(lhs), Value::Bool(rhs)) => {
Ok(Rc::new(RefCell::new(Value::Bool(lhs == rhs))))
}
(Value::Int(lhs), Value::Int(rhs)) => {
Ok(Rc::new(RefCell::new(Value::Bool(lhs == rhs))))
}
(Value::String(lhs), Value::String(rhs)) => {
Ok(Rc::new(RefCell::new(Value::Bool(lhs == rhs))))
}
(Value::Array(lhs), Value::Array(rhs)) => {
Ok(Rc::new(RefCell::new(Value::Bool(lhs == rhs))))
}
_ => Err(JumpStmt::Error(EvalError::Type)),
}
}
InfixOpKind::NotEq => {
//...
データ型
これは Momonga の(内部的な)データ型の定義です。また、 Momonga の型システムの基盤と言えるものかもしれません。
例えば、先述の Momonga の式評価におけるデータ型ごとの等価演算 ==はそもそも Rust の PartialEq であることがここでわかります。
#[derive(Debug, PartialEq, Clone)]
pub enum Value<'a> {
Bool(bool), // 真偽値
Int(i64), // 整数型
String(RefCell<String>), // 文字列型
Array(Array<'a>), // 配列
None, // null相当の`none`
Func { // 関数
params: &'a Vec<crate::ast::Ident>,
block: &'a crate::ast::BlockStmt,
},
Builtin( // ビルトイン関数
i64, // Number of arguments
fn(BuiltinArgs<'a>) -> BuiltinReturn, // Function itself
),
}
ただし、プログラマーが扱える型、真偽値、整数型、浮動小数点型(開発中)、文字列型、配列、null 相当のnoneの 6 つです。関数は宣言しかできず、式として扱えないので、ファーストクラスのデータ型としては扱われないという言い方になるかと思います。
null 相当のnone
null相当の機能の実装は迷いましたが、メジャーな言語が実装しているので理解すべき概念として実装してみました。
ただ、Momonga のnoneは毎回ヒープ割当して生成してしまっているので非効率です。none同士の等価/非等価演算も抜けているので、シングルトンなどで none を生成して、
none == none; // true とすべきだが現状は Type error
とすべきですが、この辺は課題ということで・・・
統合テスト
Rust 流で単体テストは各モジュールに書いていますので、こちらは統合テストです。実際の Momonga コードを実行して動作確認しています。
プログラミング言語ほど容易にデグレが発生するソフトウェアもないと思いました。テスト駆動は必須ですね。今回は Rust 入門者の私が言語仕様もブレブレの状態で実装が進んだので、理想的な開発フローにはなりませんでしたが、要所でテストを挟みながらなんとか壊れないように実装していきました。最終的には、テストケースは結構カバーできたと思います。
実用されている言語だとどのくらいのテストを行うのだろう、というのが気になるところですが、例えば ECMAScript では テストスイートとしてtest262があるようです。
おわりに
プログラミング言語に対する理解が深まったと同時に、ちゃんと実装するのはめちゃ大変ということがわかりました。